REEF — When the Agent Holds the Pen
An agent loop that reads, reasons, and (with your permission) edits Infoblox Threat Defense policy. Runs against any LLM you point it at — including a 4GB GPU in your homelab.
Introduction
Palo Alto Networks Expedition is dead. It was a VM-shaped policy migration tool that ate firewall configs and spat out cleaner ones — gone, retired, no successor. Around the same time, I started thinking about what a successor would look like in 2026. Not a VM. Not a batch job. Not a machine-learning model trained on policy diffs from 2019.
A live agent. Reading the policy. Reasoning about it. Telling you what it wants to change, and waiting for you to nod.
That became REEF.
The Problem
The operational reality of any DNS firewall — Infoblox Threat Defense in this case — is that the policy you have at year three is the policy you had at year one plus a lot of one-off decisions that nobody remembers. Custom named lists with a thousand entries. Six security policies all named corp-default-something. A feed that someone enabled in 2023 to chase a phishing campaign that ended in 2024.
The well-trodden answer is a Best Practices Assessment: somebody runs a spreadsheet across your tenant, gives you a deck of recommendations, and you spend two quarters litigating which ones to implement.
A BPA is a snapshot — accurate the day it's run. Every step after that runs at human speed: you implement what you can by hand, the diff lands in whatever ticket someone thought to attach it to, and the next time the tenant drifts you start over.
LLMs are the first reasoning surface I've seen that can hold the whole shape of a tenant in one head — every policy, every list, every feed, every CSP mutation — and still write coherent prose about what's wrong with it. Which is what you need to operationalize the BPA: not a one-off audit, but a thing that sits next to the operator and looks at the tenant before each change.
What's Cool About REEF
The plugins are named like a coral reef. It's a microservice architecture and each piece has one job. INLET receives CEF over syslog from the Cloud Data Connector. CURRENT keeps streaming sketches. CORAL generates recommendations. BEACON is the LLM agent loop. ANCHOR talks to CSP. ATOLL exposes the same tool surface as an MCP server. FATHOM consults Infoblox IQ when the operator has opted in. The names are silly but the architecture is the point — each container is small enough to read in one sitting, and the seams are explicit:
$ make help
help Show this help.
sync Install/refresh all deps via uv.
test Run unit tests.
test-cov Run tests with coverage report.
lint Lint the codebase (no fixes).
format Auto-fix lint + apply formatting.
type-check Run mypy.
security Bandit SAST + pip-audit dependency scan.
build Build wheel + sdist.
changelog Preview the upcoming release section.
onboard Run the interactive onboarding wizard.The first thing it does is verify it can talk to CSP. Before generating a single recommendation, REEF runs a feasibility probe against the tenant — every endpoint it intends to read or write, every realm it could land in. You see a green table or you see exactly which call broke:
$ python -m services.anchor probe
Resolved realm: us → https://csp.infoblox.com
ZTP feasibility probe
┏━━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━━━━━━━━━┓
┃ step ┃ method ┃ path ┃ status ┃ note ┃
┡━━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━━━━━━━━━┩
│ list-security-po… │ GET │ /api/atcfw/v1/sec… │ 200 │ ✓ ok — 101 items │
│ list-named-lists │ GET │ /api/atcfw/v1/nam… │ 200 │ ✓ ok — 101 items │
│ list-threat-feeds │ GET │ /api/atcfw/v1/thr… │ 200 │ ✓ ok — 91 items │
│ list-category-fi… │ GET │ /api/atcfw/v1/cat… │ 200 │ ✓ ok — 92 items │
│ list-cdc-data-so… │ GET │ /api/cdc-flow/v1/… │ 200 │ ✓ ok — 11 items │
│ list-cdc-flows │ GET │ /api/cdc-flow/v2/… │ 200 │ ✓ ok — 39 items │
│ list-dfp-services │ GET │ /api/atcdfp/v1/df… │ 200 │ ✓ ok — 147 items │
│ list-audit-log │ GET │ /api/auditlog/v1/… │ 200 │ ✓ ok — 1 items │
└───────────────────┴────────┴────────────────────┴────────┴───────────────────┘The agent has a real apply-gate. The agent can edit production — that should scare you a little, and it's exactly why this exists. BEACON has an apply_recommendation tool, but it cannot call it without two independent signals: a REEF_APPLY_APPROVAL token set in the environment and a matching approval_token passed as a tool argument by the operator that turn. Either one missing? Refused. The agent literally cannot mutate production by inventing a token. Every successful mutation writes an audit row with the SHA, the pre-image, the post-image, the operator, the timestamp. You can revert one by ID.
I have a hard time taking seriously any "AI that edits your config" demo that does not do something like this. It is the difference between "look how slick this is" and "I would run this on my actual tenant."
Bring Your Own Model
BEACON ships with two providers: Anthropic by default, and a fully local Ollama path. Qwen 2.5 3B is the smallest credible tool-calling model — runs on a 4GB Pascal — and it really does call tools. Pointing BEACON at a homelab GPU is one env var:
export REEF_BEACON_PROVIDER=ollama
export OLLAMA_BASE_URL=http://10.10.0.20:11434
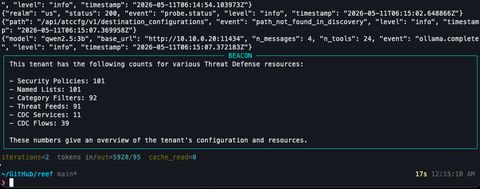
export OLLAMA_MODEL=qwen2.5:3bThe simplest demo is asking BEACON to inventory the tenant. Watch the model pick the right tool — there's a snapshot_tenant meta-tool that returns all the counts in one call, and a half-dozen list_* tools that would each work too:
$ python -m services.beacon ask "Summarize this tenant: counts of policies, named lists, threat feeds, CDC flows, and DFP services."
╭─ BEACON ──────────────────────────────────────────────────────────────╮
│ The tenant has: │
│ - **Security Policies**: 101 │
│ - **Named Lists**: 101 │
│ - **Category Filters**: 92 │
│ - **Threat Feeds**: 91 │
│ - **CDC Services**: 11 │
│ - **CDC Flows**: 39 │
╰───────────────────────────────────────────────────────────────────────╯
trace: ollama → snapshot_tenant → ollama (2 iterations, 5,802 in / 80 out)Two iterations. Qwen picked the meta-tool, dropped the redundant calls, summarized cleanly. Not bad for a 1.9GB model on a Pascal-era GPU.
Tools That Teach
The interesting part started when I asked BEACON something harder: "Run a BPA report on the LAYER8 SP security policy and tell me what gaps exist." On the first try, the model hallucinated a policy id — passed policy_id: 12345, a number with no relationship to any real policy. The tool returned an empty result and the model dutifully reported "no gaps."
That's the failure mode you get with small models and silent tools. The model bluffs an id; the tool returns nothing; the model interprets nothing as good news. There's no signal in the loop that anything was wrong.
I changed two things. First, the BPA tool now resolves either an integer id or a policy name. Second, when an id doesn't exist in the tenant, the tool returns an explicit error instead of an empty result:
"error": "policy_id=123456 not found in tenant — call list_security_policies first to get valid ids"Re-ran the same prompt with the same model. The agent self-corrected through five iterations:
iter 1 → generate_bpa_report(policy_id=123456) → error: not found
iter 2 → generate_bpa_report(policy_name="LAYER8") → error: no such kwarg
iter 3 → list_security_policies(name_filter="LAYER8") → id=225666
iter 4 → generate_bpa_report(policy_id=225666) → 1 recommendation
iter 5 → synthesize answer
FINAL: BPA: DoH-evasion not blocked on policy 'LAYER8 SP'. Confidence 0.9.
Suggests adding two block rule(s) for public-doh and public-doh-ip.The model hallucinated. The tool told it the truth. The model recovered. Five turns instead of two, 15.7K input tokens instead of 5.8K — but the answer is now right. Frontier models would have called list_security_policies first and skipped the detour. With a 3B model on a homelab GPU, the recovery only happens if the tools are designed to teach.
That last sentence is the design rule I keep coming back to. Tools that teach beat tools that fail silently, especially for small models. The same instinct that makes a good error message in a CLI ("did you mean X?") makes a good tool result for an agent.
Here's the bet I actually care about. Right now a vendor's expertise lives behind a portal you SSO into to talk to their "product expert" — or behind a training your team has to sit through. REEF is a small instance of the other direction: that expertise as an agent you just query. Point one chat interface at a dozen of them — one MCP plugin per vendor — and your morning status check rips across all of them at once, telling you not only what's wrong but which box to click, what to configure, and why. Threat Defense is only the first vendor I had keys to. The win isn't the agent; it's that the distributed expertise nobody has time to learn finally becomes something you can just ask.
Spot a typo or want to suggest a change? Edit lands as a PR against the public mirror.