Agentic Workloads on an Infoblox NIOS-XaaS POP
Bypassing agent registries to individually advertise agentic workloads on existing infrastructure.
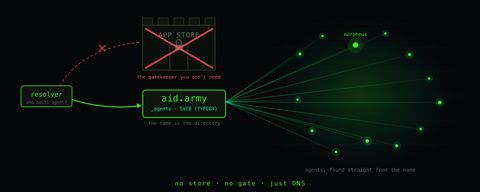
When you put a managed DNS service behind your own front door, the reflex is to stand up edge name servers as stealth secondaries — they pull the zone over AXFR, answer the public, and shield the "real" primary behind them. I wanted the front door to be a hallway: take the query at the edge and forward it down the tunnel to the primary.
That sounds like laziness until you look at what the primary actually is. The whole stealth-secondary dance exists to solve a problem UDDI's XaaS doesn't have, so my entire edge collapses from "a fleet of name servers" down to "a tunnel and a relay."
The availability was never going to be my problem to solve, and that matters before anything else here. A NIOS-XaaS POP terminates two IPsec tunnels — dual Cloud Service IPs — behind one anycast front, against a primary whose durability is backend database replication.
I shipped one VM on one tunnel, temporarily. Not because the design is wrong but because I couldn't reach it the clean way — the tenant didn't have direct VPC peering turned on. Instead, with an afternoon and a cost cap, I built a relay edge.
The Pattern I Didn't Want
A stealth secondary is a name server that's authoritative for a zone but isn't listed in the zone's NS set. It exists for two honest reasons: to put answering capacity close to clients, and to keep the writable primary off the public internet. To do its job it has to hold the zone — which means AXFR/IXFR from the primary, NOTIFY to keep it fresh, SOA timers governing refresh/retry/expire, and a standing assumption that two copies of the data can disagree for a window and you'll live with it.
But then you need to also live with the idea of delayed cache invalidation, propagation timers, and more DNS... fun. That's a lot of moving parts whose entire purpose is reconciling two copies of something.
The pattern secondary fabric earns its keep when your primary is a single fragile box you're terrified to expose. It's cruft when your primary isn't that — when "the primary" is a managed service that already solved durability a layer below you.
What the POP Actually Is
NIOS-X as a Service is one service, and a service I'm interested in now that it natively supports DNS AID records. From the console you configure one DNS server as the primary for a zone; the durability lives underneath it, in backend database replication, not in a fan-out of secondaries you operate. There's no zone-transfer relationship for me to recreate at the edge because there's no second authoritative copy in my half of the design — the redundancy already happened, a layer down, before the query ever reached me.
So the question flips. It isn't "how do I replicate the zone to the edge so the edge can answer?" It's "how do I get a public packet to the primary and back?" The primary's DNS capability listens on a private Service IP — a /32 that only exists inside an IPsec tunnel between my edge and the POP. Nothing on the public internet can route to it. My entire job is to be the thing that can reach it, and to lend it a public face.
The platform expects you to reach it redundantly. A POP hands you two Cloud Service IPs (two IKE responders against the same primary) so the designed deployment is two edge VMs across two AZs, each holding its own tunnel, behind one anycast front. Lose a VM, an AZ, or a tunnel and the other path still answers and the primary never noticed.
The cleanest integration skips the VMs entirely and peers your VPC straight into the POP (Transit Gateway or Cloud VPN), so AWS routing carries the traffic to the Service IP with no relay in the middle. I didn't have access to direct peering on this tenant, so I built the relay-VM edge instead — and then, to ship in an afternoon under a cost cap, ran exactly one of those VMs on one tunnel. The mechanics below describe one VM's path; the design runs two of them.
Framed that way, the edge stops being a name server and becomes plumbing.
The Ingress, End to End

This is the designed topology — two VMs, two tunnels, the POP terminating both. Four tiers, public to private, and none of them is authoritative for anything.
The Anycast Front Door
The two IPs at the registrar aren't a server — they're AWS Global Accelerator static anycast addresses, announced from AWS edge locations worldwide via BGP. A resolver in Frankfurt and a resolver in São Paulo both send to the same 76.223.105.37, and BGP delivers each to the nearest AWS edge, where the packet enters Amazon's backbone instead of the public internet for the rest of the trip. That's the latency win: the slow, lossy public-internet segment is just resolver-to-nearest-edge, not resolver-to-us-east-1.
It listens on UDP and TCP 53, plus TCP 853 for DoT. Crucially, Global Accelerator preserves the client source IP end to end — the POP sees the real resolver address, not a proxy's, which matters for anything that ever wants to reason about who's asking (well... for as much as source client IP is trustworthy, that is 🤓). Two anycast IPs means the glue (ns1/ns2.aid.army) points at two independent entry addresses fronting the same accelerator — redundant doorways, one building.
The Load Balancer
Behind the accelerator sits a Network Load Balancer with a single TCP_UDP listener on 53 (and a TCP listener on 853). NLB is L4 — it does not parse DNS, it hashes the 5-tuple (src IP, src port, dst IP, dst port, protocol) to pin a flow to a target and forwards the packet. Cross-zone load balancing is on, so an NLB node in either AZ can reach the target regardless of which AZ the target lives in.
The target is registered as an instance target, and that detail decides whether anything works at all: with an instance target the NLB does not SNAT, so the packet arrives at the box with the resolver's real IP intact and the return path is symmetric through the box's own stack. Health-checking a UDP service is impossible directly, so the target group probes TCP/53 — if dnsdist is listening on TCP it's almost certainly serving UDP, and that proxy is good enough to pull a dead box out of rotation.
The Relay
The target box runs dnsdist — and dnsdist here is not a resolver and not authoritative. It holds no zone, keeps no cache, answers nothing itself. Its entire config is "take the query, send it to this backend, send the answer back":
setLocal("0.0.0.0:53")
newServer({address="10.99.0.10:53"}) -- the POP Service IP
setACL({"0.0.0.0/0"}) -- public; the edge IS the public faceTwo non-obvious things bit me here. First, systemd-resolved ships a stub listener on 127.0.0.53:53 that quietly owns the port — dnsdist can't bind 0.0.0.0:53 until you set DNSStubListener=no and restart it. Second, the security group has to allow 53/853 from 0.0.0.0/0: an instance target means client traffic hits the box's own SG, not just the NLB's, and the reflex of "only allow 53 from the VPC" silently blackholes every real query.
Into the Tunnel
When dnsdist forwards to 10.99.0.10:53, that packet leaves the host stack and hits a strongSwan xfrm policy: destination 10.99.0.10/32 matches the tunnel's traffic selector, so the kernel encapsulates it in ESP and ships it over the route-based IKEv2 tunnel to the POP. NAT-T is mandatory — the box is behind AWS's 1:1 NAT (its EIP isn't a local interface address), so IKE and ESP ride UDP/4500. The IKE responder on the POP side keys partly on the initiator's source IP, which is exactly why the box needs a stable EIP registered in the Access Location: a rotating public IP fails the match with NO_PROPOSAL_CHOSEN and the tunnel never comes up. The relay's forward is the only thing that ever touches the Service IP; nothing else in the VPC has a route to it.
A Query, Packet by Packet
Put it together and a single agent.aid.army lookup makes this round trip:
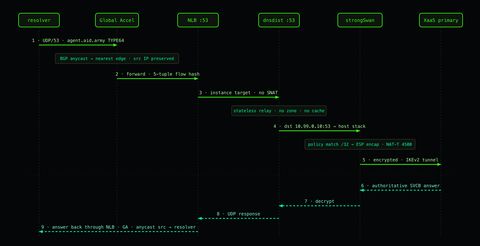
Notice how little of this is DNS. Exactly two hops parse the query as DNS: the resolver that asked, and the POP that answered. Everything in between — anycast routing, NLB flow-hashing, dnsdist's forward, the kernel's ESP encapsulation — is moving an opaque UDP payload from a public address to a private one and back. The edge never knows or cares that the bytes are a SVCB record.
The proof it works is boring, and boring is what I wanted — a query to a public resolver returns the right answer, and the path it took was resolver → registry → anycast → NLB → tunnel → POP: dig +short @8.8.8.8 test.aid.army A
DNS-AID, Native vs Hand-Rolled
The reason aid.army exists at all is agent discovery, and that's where the interesting difference shows up. DNS-AID publishes an agent's coordinates as a SVCB record, so a client can find an agent's catalog, protocols, and integrity hash from a single DNS query instead of a directory it has to trust out of band.
I've published the same agent two ways. On darknetian.com it lives on Cloudflare, where I hand-assembled the SVCB record — the target name, the ALPN, and the custom SvcParams for the catalog URL, the catalog hash, and the protocol list, packed into the wire format by hand. On aid.army it lives on the XaaS POP, where the platform models the agent and emits the record for me.
Query both and you get byte-identical answers — dig returns the exact same TYPE64 RDATA from either zone. Here it is on the wire, then decoded:
;; raw RDATA (155 bytes)
0001 086D6F7270686575730A6461726B6E657469616E03636F6D00
0001 0003 026832
FF78 003B 68747470733A2F2F...2D636174616C6F672E6A736F6E
FF79 002B 634B524F7533394B...35693045
FFDC 0007 6D63702C613261
;; decoded
agent.aid.army SVCB 1 morpheus.darknetian.com (
alpn=h2
key65400="https://morpheus.darknetian.com/.well-known/ai-catalog.json"
key65401="cKROu39KtkiqqK6FR-iCKEvT7PzlElR-h90-8ywx5i0E" ; catalog sha256
key65500="mcp,a2a" ; protocols
)Read the bytes left to right: 0001 is the SvcPriority. The next run is the target name in DNS wire form — 08 length, morpheus, 0A length, darknetian, 03 com, 00 root. Then the SvcParams in ascending key order: key 0001 (alpn) length 3 carrying 02 h2; key FF78 (65400) length 003B=59 carrying the catalog URL; key FF79 (65401) carrying the base64url SHA-256 of that catalog; key FFDC (65500) carrying mcp,a2a, the protocols this agent speaks. SvcParamKeys must appear in strictly ascending numeric order or the record is malformed — get that wrong by hand and a strict parser drops the whole answer.
Identical bytes, two very different ways of producing them. A generic DNS provider can carry DNS-AID — SVCB is just a record type, and if you're willing to hand-pack the SvcParams in ascending key order with the right length prefixes, Cloudflare will serve the bytes. But carrying the bytes and understanding the thing are different jobs.
On the POP I describe an agent — name, catalog, protocols — and the platform emits a correct record. On Cloudflare I describe a byte layout and hope I counted the lengths right and sorted the keys. When the draft adds a SvcParam, one of those two paths updates itself and the other one is me, again, with a hex editor.
The Tradeoffs, Named
I collapsed the designed two-VM, two-tunnel deployment down to a single box on a single tunnel with a $50/mo budget cap. Here's what that corner-cut actually costs, line by line.
Entry-Point HA Versus Data-Plane HA
What my workaround gives up is entry-point redundancy. One edge VM means a relay outage is a resolution outage until it reboots; one tunnel means no second IKE path if the peer drops.
What no version of this gives up is data-plane redundancy, and that's why even the degraded single box was acceptable to ship for a homelab. The durability lives in the POP's backend replication, so the thing that's genuinely hard to rebuild — the authoritative data — was never riding on my box at all.
I'm risking a few minutes of downtime on a cattle-grade relay, not risking the zone. A stealth-secondary design inverts that: it spreads the data across boxes you operate, so every edge node becomes a place the data can be silently wrong. I'd rather own a dumb pipe that fails loudly than a smart replica that drifts quietly.
Latency, MTU, and the Fragmentation Trap
The performance cost is the relay hop. A co-located authoritative server answers in one round trip; here the query crosses the anycast edge, the NLB, the box, and the encrypted tunnel before the primary sees it. The anycast front end claws most of that back by terminating the client near home and carrying the rest on Amazon's backbone, but the tunnel leg is real added latency.
The subtler trap is MTU. A SVCB answer with a long target, several SvcParams, and DNSSEC signatures can blow past 512 bytes, so EDNS0 buffer sizes and UDP fragmentation are in play — and then the packet has to fit inside an ESP tunnel that's already eaten ~50–60 bytes of overhead off the path MTU.
Oversized UDP either fragments (and fragments love to get dropped) or trips the truncation bit and forces a TCP retry. The TCP_UDP listener and the TCP/853 path exist partly so that fallback has somewhere to land. For a discovery record that's queried, cached against its TTL, and re-queried hours later, the added hop is in the noise; under that calm is a real MTU budget you don't get to ignore.
The Cost
Steady state lands around $46/mo, which is why $50 is the ceiling:
| Component | USD per month |
|---|---|
| t4g.small edge box | 15 |
| Network Load Balancer | 16 |
| Global Accelerator | 18 |
| EIP and data | 3 |
The accelerator's flat $18 is the single biggest line — the price of anycast — and the one I'd most want to amortize across more than one domain.
What's Next
There's a spectrum here, and I shipped the bottom rung of it.

The nearest fix is the designed topology: the second VM in the second AZ, the second tunnel into the POP's other Cloud Service IP, and entry-point HA comes back for the price of one more t4g.small. Better still, the POP can peer eBGP over the tunnel, so the paths aren't two static failovers but backend tunnel peering — multiple IPsec paths to the same primary with BGP steering between them, reconverging instead of going dark.
The cleanest option erases the edge VMs entirely: peer the VPC straight into the POP over Transit Gateway or Cloud VPN, the path I couldn't take this time for lack of access.
So here's the claim, and I'll take the rebuttal: when your primary is a managed service with its own replicated backend, the edge-secondary layer isn't resilience — it's a second system to keep honest. The availability you actually want is already in the platform. Don't rebuild it at the edge; just forward the tunnel, and spend the saved complexity on the thing that's genuinely yours to lose — the front door, not the data behind it.
Spot a typo or want to suggest a change? Edit lands as a PR against the public mirror.